警告:
成功:

《旧约圣经》中有记载:
在天下人的口音、言语都是一样时,他们要建造一座城和一座通天塔,以此传扬盛名,免于分散。
耶和华说:“看呐,他们成为一样的人民,都是一样的言语,如今既做起这事来,以后他们所要做的事就没有不成就的了。我们下去,在那里变乱他们的口音,使他们的言语彼此不通。”
于是,众人的塔半途而废,人类也各奔东西。
《圣经》以巴别塔之寓,解释了不同的种族和语言因何存在,如今,人们用这座未能建成的通天高塔,象征语言不通带来的混乱隔阂。
探险、贸易、战争,让人类之间彼此发现、了解、融合,而互不相通的语言却成为沟通的绊脚石。
出于理想,1887 年犹太人柴门霍夫以印欧语系为基础创建世界语(Esperanto),试图以此消弭国际交往中的语言障碍。但时至今日,使用世界语的人数,仍不足世界人口的 0.03%。
没有使用环境、没有文化和历史基础的世界语,推进速度与愿望相去甚远。于是,有人转而认为英语才是世界语。
人人学习英语?过去20年的实践,似乎并没收到理想的效果。
一个更快的解决方案也许是:人类或许可以求助于机器,让交流畅通无阻。
机器翻译之难
自然语言,是人类智慧的结晶。语言之后,才有了精准的信息记忆、严密的逻辑思维、丰富的情感表达、社会协作等璀璨的人类文明。
翻译,是语言中最经典的问题,其既包括语言的理解,也包括语言的生成。
然而,自然语言理解,是人工智能所面对的最困难的问题之一。
为什么难?
第一,建模难。自然语言是人类经过数千年进化而来的。当一个婴孩有一天突然蹦出了一句“爸爸妈妈”,你并不知道这个过程是如何发生的,怎么建模?
第二,算法的片面性。并非所有事物都可以数字化,人类的沟通绝不仅仅是依赖于目前算法所能处理的信息。人们能够“理解”彼此,除了词句本身,也饱含了对物理世界的知识积累和人生阅历——当两个人的生活环境全然不同时,你或许可以听懂对方说的每一个字,但发生真正的理解和深层次的沟通很难,更何况人与机器之间的“理解”。
“语言是所有智能文明的必然产物,”可纵观自然语言理解与翻译史,段亦涛告诉了Xtecher,“充满着波折与质疑。”
在最早期,人们寄希望于研究语言规则,用规则来翻译,却发现语言有非常强的多样性,而系统必须编码所有可能的变化,导致无穷无尽的规则出现;第二个阶段,人们寄希望于统计数据,所有规则让机器自动学习过来;而如今的第三代研究方式,即以深度学习技术为基础的神经网络翻译,同样是基于统计数据,但是采用更强大的模型,使得机器能够更准确地学习到语言中的规律,翻译质量获得非常显著的提升,在某些领域已经接近人类翻译的水平。
深度学习在机器翻译领域获得了巨大成功,以至于有人认为彻底解决机器翻译问题的曙光就在眼前了。
事实上,机器翻译经历了漫长蹉跎的进阶史。
时间倒退至二十世纪三十年代初,法国科学家G.B.阿尔楚尼最先提出了用机器来进行翻译的想法。
1946年,世界上第一台现代电子计算机ENIAC诞生。随后不久,信息论的先驱、美国科学家Warren Weaver于1947年提出了利用计算机进行语言自动翻译的想法。1949年,Warren Weaver发表《翻译备忘录》,正式提出机器翻译的思想。

随后十年,机器翻译研究热度不断上升。美国、前苏联及一些欧洲国家,均对机器翻译研究给予了相当大的重视,机器翻译一时出现热潮。
然而,正当一切有序推进之时,尚在萌芽中的“机器翻译”研究却遭受了当头一棒。
1964年,美国科学院成立了语言自动处理咨询委员会(Automatic Language ProcessingAdvisory Committee)。委员会经过2年的研究,于1966年公布了一份名为《语言与机器》的报告。该报告全面否定了机器翻译的可行性,并宣称“在近期或可以预见的未来,开发出实用的机器翻译系统是没有指望的”。受此报告影响,各类机器翻译项目锐减,机器翻译的研究出现了空前的萧条。
直到二十世纪七十年代中后期,随着计算机技术和语言学的发展以及社会信息服务的需求,机器翻译才开始逐渐复苏。由此,业界研发出了多种翻译系统,例如 Weinder、EURPOTRAA、TAUM-METEO等。不过,当时业界采用的办法颇为笨拙:将语句中逐个词语替换成词典中的解释。这种翻译效果显然无法满足人们的需求,也进一步向人们宣告着:机器翻译绝非易事。
再后来,随着1993年IBM的Brown和Della Pietra等人提出了基于词对齐的翻译模型,统计翻译模型(SMT)方法正式诞生。
统计翻译模型(SMT)不依赖于人制定的规则,而是通过对大量的平行语料(由原文文本及其平行对应的译语文本构成的双语语料库)进行统计分析,构建统计翻译模型。相比从前基于规则的模型,统计翻译模型极大提升了翻译质量,因此过去几年间,主流翻译引擎都以基于短语的统计翻译为核心。
“统计翻译模型经历了很长一段发展时期,但除了带来初期翻译质量的明显提高,后期基本涨势成平。直到近几年,基于神经网络的翻译模型(NMT)才开始崛起。”段亦涛告诉Xtecher。
近几年,神经网络翻译为机器翻译领域打开了一扇新的窗口。
神经网络的诞生,源自人类一个朴素而原始的初衷——想让机器去模拟人脑神经系统。神经网络的一个重要特性是“从环境中学习”,基于神经网络的翻译模型,通过对人脑的基本单元——神经元的建模和联接,探索模拟人脑神经系统功能的模型,期望研制一种具有学习、联想、记忆和模式识别等智能信息处理功能的翻译系统。
神经网络受到了掌握多门语言的人类在翻译过程中大脑中发生的模式识别过程的启发,可以实现更自然的语音翻译。
“这一过程类似于人在翻译:先理解句意,再生成翻译。”
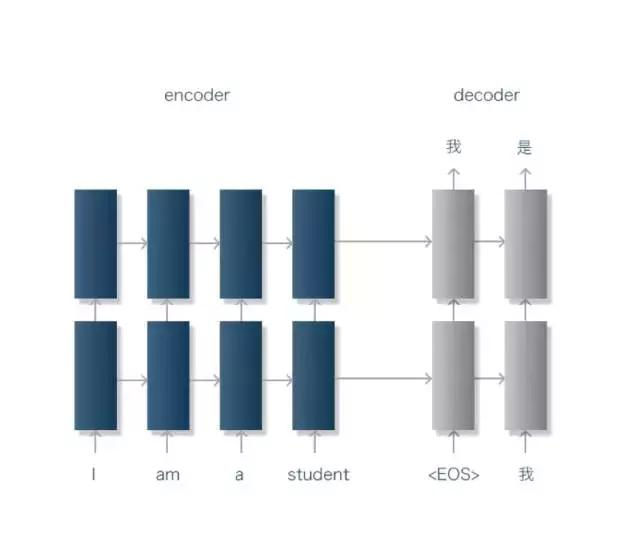
NMT翻译原理
对比神经网络翻译模型与上一代统计翻译模型,段亦涛告诉Xtecher,前者有三点优势:
首先,统计翻译模型就像一个由多个组件构成的机器,每个组件完成各自的目标,各个组件的输出人为地拼装起来,完成翻译流程。而神经网络机器翻译模型是一个端到端的模型,其更像一个有机整体,里面的所有参数都向着一个共同的目标统筹优化,它们之间的配合更加协调。
其次,统计翻译模型用离散的one hot encoding的方式来表达一个词。这种方式的本质是用一个编号来识别每一个对象,它不能够表达词与词之间的关系,因为任意两个one hot向量的差异都是一样的;而神经网络翻译模型是用一个在实数域中的向量来表达一个词,向量的每一个元素都可以是任意的实数。向量之间的距离、方向等可以表达词之间的关系,整体表达的信息更为丰富。例如,在神经网络翻译模型中,一个单词已经不再仅仅是一个编号,而是一个包含500个维度的向量,其本质是500组数字,而每一个数字都反映了这个单词的某一个方面。
最后,统计翻译模型的拼凑感较为明显;神经网络模型翻译出的内容更加流畅,能够更好地利用上下文处理一词多义的现象。
简言之,相比统计翻译模型可能会导致翻译出来的语句笨拙而迂回,神经网络模型能够提供更流畅、听起来更有“人味”的翻译。
“神经网络翻译模型在模型结构上模拟了人脑,其中参数的优化过程也类似人的学习过程。”
有道的突围
面对神经网络翻译的优势,谷歌、微软、百度、科大讯飞等都加快将神经网络应用于机器翻译领域的脚步,谷歌更表示会将神经网络机器翻译技术推广到GoogleTranslate现在支持的全部103个语种中。
毕业于北航飞机设计专业硕士的段亦涛,在伯克利读博期间由于校内没有合适的研究项目,从而转向计算机系,他的论文方向是分布式计算中的隐私和加密技术。
事实上,他留美期间,已在有道兼职负责搜索相关的机器学习领域,随后回国,便全身心地投身到了机器翻译的浪潮之中。
段亦涛所面对的竞争对手是谷歌这样大刀阔斧行进的巨头。不过,他对有道不久前推出的神经网络翻译仍颇有信心。在他看来,有道的优势有两个方面:
优势之一显然是数据积累。有道作为国内第一批提供机器翻译服务的互联网公司,从2008年正式推出到现在已近十年。十年间,有道一直聚焦于中文与其他外语之间的翻译,通过不断提升机器翻译的质量,吸引了大量用户,积累了海量的语料和数据,这些数据对神经网络翻译模型的持续优化十分有用。
“目前主流的神经网络翻译模型大体框架都是一致的,但其中细节和内部机制的作用方式有所差异,这也是造成翻译结果更为人性化的关键。而这些细节和不同机制需要大量的实验及尝试才能确定,这就需要大量数据支撑。”
优势之二,是有道比谷歌在翻译目标上更加专注。谷歌提供全球服务,支持多种语言的翻译。而有道的目标是服务中国用户,翻译聚焦于中文和其他语言之间,更加理解国人的语言习惯。
从翻译界通用的BLEU值评价指标来看,有道神经网络翻译在新闻文章、英语学习及口语等场景下的中英翻译,做得比国际同类产品更加出色。
在英语学习场景下的翻译数据盲测结果显示,此次在有道上线的NMT,其英译中和中译英的BLEU值均领先了同行7个多百分点。
在新闻文章翻译场景下,有道上线的NMT同样表现不俗,英译中的BLEU值超同行6个百分点,中译英也超其8个百分点。
“尽管机器翻译在近两年进展较快,但其仍有很长的路需要走。”尽管有道处于业内领先位置,段亦涛仍保持着对机器翻译的敬畏之心。
谈及有道神经网络翻译模型之后的发展方向,段亦涛告诉Xtecher了三点:
首先,需要持续提高神经网络的翻译质量。
目前的翻译只是机器捕捉数据规律,然后对句子进行直译。若数据中存在表达情绪的词语,机器学习可以使翻译出的句子带有与情绪相关词语,但实际中的语言习惯,通常情绪只表达在声调、语调上,此时,翻译出的句子很难表达出原意。
“未来有道也会结合翻译的诸多场景、情景,使得翻译更为人性化,满足不同的翻译需求。”
此外,机器翻译也要与人工智能的不同分支相结合。
目前有道神经网络翻译已加入图像翻译及语音翻译,图像翻译即根据拍摄图片即时识别出其中文字并翻译出来。

“有道致力于将技术与AI结合,尝试诸如在语音数据基础上直接进行翻译,而非先将语音内部转化成文字,再用文字进行机器翻译。在此基础上提炼出来的将不仅仅是文字,可能会将语句中的情感等额外信息翻译出来。”
最后,目前上线的神经网络模型致力于实现中英互译,之后也会拓展到其他语种,如中俄、中法互译等。
段亦涛告诉Xtecher,中英两种语言是常见需求,因此相关数据量巨大。而其他语种由于使用人数远少中英互译,得到的数据量较少,机器翻译效果相比中英互译效果较差。
“要想把机器翻译做好,需要更好地理解人对翻译的需求,并将这些需求与翻译结果、翻译机制进行对比,找出其中欠缺之处,针对性地进行优化。”
不会完全取代人类翻译
现在的很多人已经不记得世界上曾经存在过一个“打字员”的职业了。
在90年代末到21世纪初的短暂时光里,伴随计算机的飞速发展出现大批打字人员。但今天,曾经无上光荣的这一职业早已被抛弃。
计算机技术的发展与普及消灭了这个最先接触计算机的职业,这真是个讽刺。
而同样的问题也出现在机器翻译领域,机器翻译最终会取代人工吗?翻译行业是否将走到尽头?
“事实上,机器翻译会对翻译行业带来巨大的冲击,但不会完全取代。”
段亦涛认为,人类对语言的学习不只是出于翻译目的,更多是去学习一门语言中的文化、情感等。而机器,显然不能理解语言中这些附属品,“或者说你也不希望机器来替代你。”
除此之外,机器翻译说到底仍是机器学习,其依赖于从大量的数据中学习对应关系——而供机器学习的数据,仍依赖于人所提供。
最后,由于专业翻译要求极高的准确性,在很多场合,机器无法承担出现错误而导致的严重后果,因此,对于专业领域的翻译工作,机器还不能胜任。
神经网络翻译内在还存在诸多问题。例如,由于神经网络翻译模式是一种端到端的从数据中统一学习的模式,词语在语意方面的信息和语法方面的信息可能会混杂一起。这一方面是有益的,因为理解原文需要同时依赖两者。但不同的场景下两者的贡献是不同的,人在阅读过程中可以利用明晰的语法规则进行调整。机器翻译目前还做不到,这在有些情况下带来一些干扰。例如,机器在翻译一个与名人同姓的普通人时候(例如Gates),就有可能翻译成名人(Bill Gates),因为后者在数据中更常见,模型就把这个姓和具体的名人进行了强关联。
段亦涛认为,目前来看,机器翻译带来的较为现实的变化,是可以大幅地降低人翻译的成本。“有道的人工翻译业务会先用机器翻译粗糙处理,然后再由人进行后续处理。”
根据有道内部数据显示,如今,通过使用神经网络模型,可以降低约一半的翻译人力成本。
《银河系漫游指南》中有一个构想:只要把一条巴别鱼塞进耳朵,就能立刻理解任何形式的语言。
语言,是人类智能最璀璨的所在。完备的语言体系,是人类世世代代进化的结晶,是全人类刻画世界、思考和交流的宝贵工具。无论技术挑战多么艰难,科技工作者们显然不忍心放弃这块宝地。虽然,目前的神经网络翻译给出了一个历史最优解,但这却远远不是能够满足人类需求的终极解法。此时此刻,包括有道在内的全球科技公司,都走在这条诱人而幽深的道路中。
(注:本文图片取自原文章,如有侵权请联系删除,谢谢!)
(来源 | Xtecher)
大赛公众号

